Operational resilience engineered into the platform.
SRE engineering, observability platforms and operational automation for organisations running cloud-native, enterprise and regulated workloads.
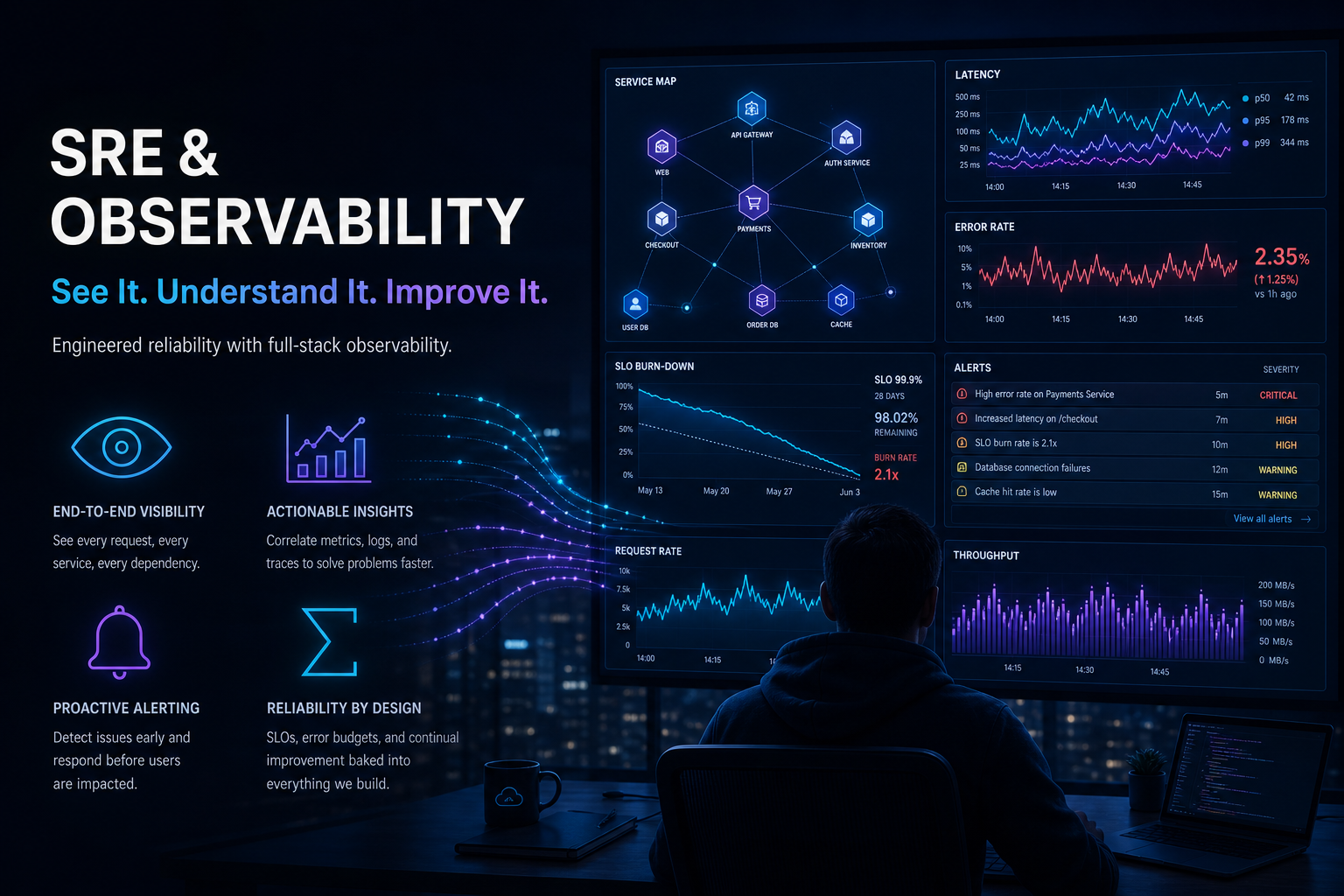
Operational visibility for production environments
Reliable platforms require more than infrastructure deployment. Observability, operational automation and incident response processes are critical for maintaining resilient production services at scale.
Antevorta delivers practical SRE and observability engineering focused on improving operational visibility, reducing incident impact and helping teams manage complex environments with confidence.
Typical engagements
- ELK and Grafana observability platforms
- CloudWatch and Dynatrace integration
- SLO and reliability engineering
- Python and Ansible automation
- Incident response improvement
- Hybrid-cloud monitoring implementation
Capabilities
Reliability and observability services
Observability platforms
Centralised monitoring and observability engineering designed for production operations and incident response.
- ELK stack implementation
- Dynatrace integration
- CloudWatch & Grafana
- Metrics & log aggregation
SLO & reliability engineering
Operational reliability frameworks focused on measurable service performance and resilience.
- SLO & SLA design
- Error budget implementation
- Availability monitoring
- Reliability reporting
Incident reduction & response
Operational workflows and automation designed to reduce incident impact and improve recovery times.
- Incident response processes
- Alerting optimisation
- Game day exercises
- MTTR improvement initiatives
Automation & operational tooling
Operational automation to reduce manual overhead and improve platform consistency.
- Python automation
- Ansible workflows
- Infrastructure operations tooling
- Automated remediation support
Delivery outcomes
Reliability improvements driven by operational insight.
Strong observability and operational engineering reduce downtime, improve recovery times and give engineering teams the visibility required to operate modern cloud platforms effectively.
Reduced MTTR and operational disruption
Improved platform visibility and monitoring
Better incident detection and response workflows
Improved operational reliability
Reduced alert fatigue and operational overhead
Operational insights across cloud and hybrid environments
Engagement approach
Operational engineering focused on long-term resilience.
Engagements range from observability assessments and monitoring platform implementation through to embedded SRE engineering and operational improvement programmes.
The objective is always practical operational improvement: reducing incident impact, improving visibility and creating sustainable operational processes for engineering teams.
Let's talk
Ready to build a platform that scales?
Book a free 30-minute discovery call to review your infrastructure and map out clear recommendations.
- 30-minute discovery call, no obligation
- Architecture review with concrete clear recommendations
- Independent consultancy, direct, hands-on advice