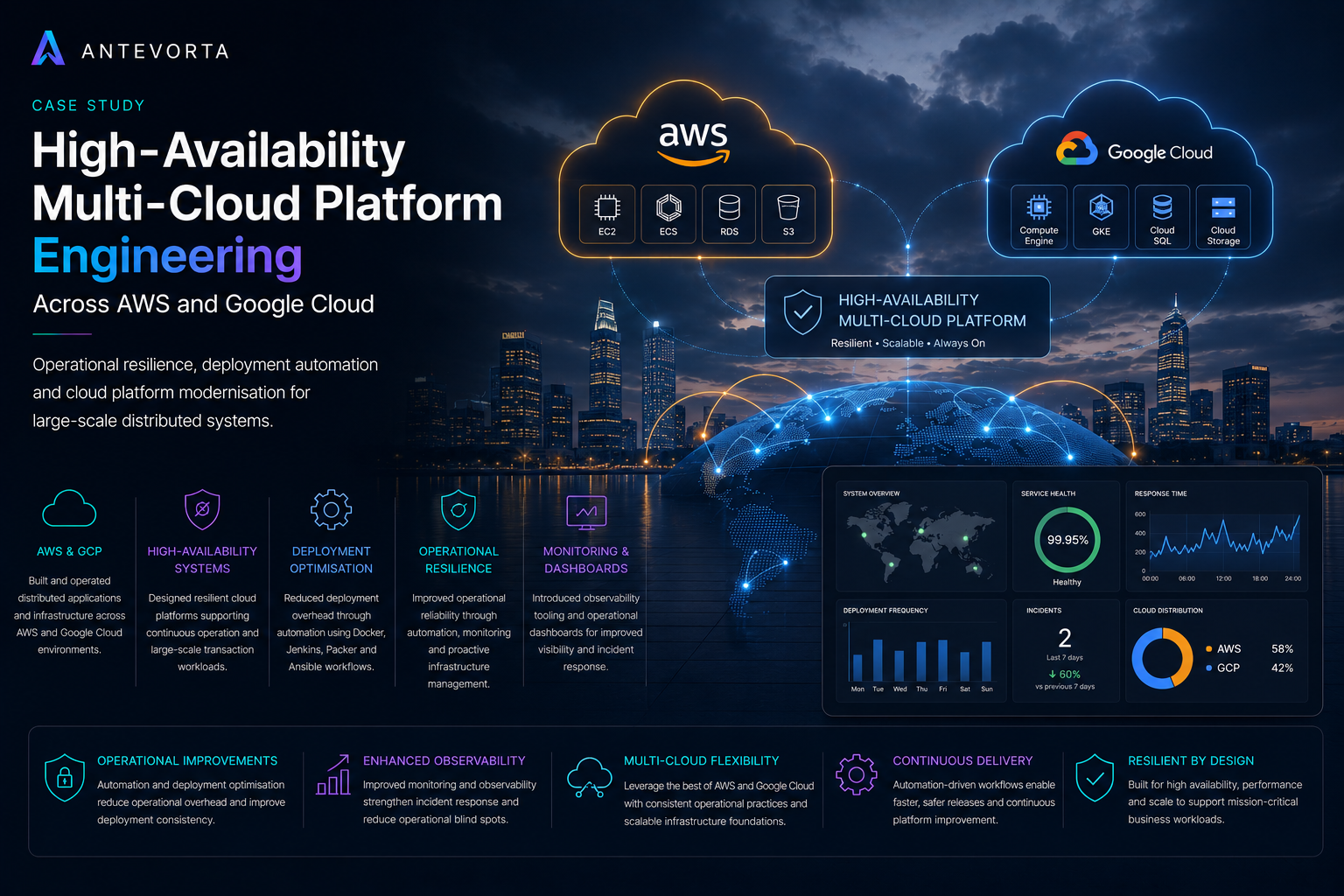
High-availability multi-cloud platform engineering across AWS and Google Cloud.
Operational resilience, deployment automation and cloud platform modernisation for large-scale distributed systems.
Challenge
Operating resilient cloud infrastructure at production scale.
The engagement focused on maintaining and improving a high-availability multi-cloud platform supporting large daily transaction volumes and continuous feature delivery.
Operational priorities included deployment optimisation, infrastructure consistency, platform resilience and improving visibility across distributed cloud systems.
Approach
Automation and observability integrated into day-to-day operations.
Distributed applications and infrastructure were operated across AWS and Google Cloud environments using automation tooling including Docker, Jenkins, Packer and Ansible.
Monitoring systems and operational dashboards were introduced to improve observability, reduce operational blind spots and strengthen incident response workflows across production infrastructure.
Focus areas
Core platform engineering areas
AWS & GCP
Built and operated distributed applications and infrastructure across AWS and Google Cloud environments.
High-availability systems
Designed resilient cloud platforms supporting continuous operation and large-scale transaction workloads.
Deployment optimisation
Reduced deployment overhead through automation using Docker, Jenkins, Packer and Ansible workflows.
Operational resilience
Improved operational reliability through automation, monitoring and proactive infrastructure management.
Monitoring & dashboards
Introduced observability tooling and operational dashboards for improved visibility and incident response.
Delivery details
Operational improvements through automation and standardisation.
Infrastructure automation and deployment optimisation reduced operational overhead while improving deployment consistency and release confidence across cloud environments.
Operational resilience was strengthened through improved monitoring, proactive observability and more consistent platform management practices supporting continuous service availability.
Multi-cloud deployment patterns enabled flexibility across AWS and Google Cloud while maintaining operational consistency and scalable infrastructure foundations.
Outcomes
Operational and platform outcomes
100K+ daily transactions supported
Accelerated deployment workflows
Reduced critical operational incidents
Improved infrastructure consistency
Enhanced operational visibility
Scalable multi-cloud platform foundations
Running complex cloud infrastructure at scale?
Antevorta provides cloud platform engineering, deployment automation, observability and operational resilience support for enterprise and high-availability production environments.
Let's talk
Ready to build a platform that scales?
Book a free 30-minute discovery call to review your infrastructure and map out clear recommendations.
- 30-minute discovery call, no obligation
- Architecture review with concrete clear recommendations
- Independent consultancy, direct, hands-on advice