High-scale gaming infrastructure engineered for unpredictable demand.
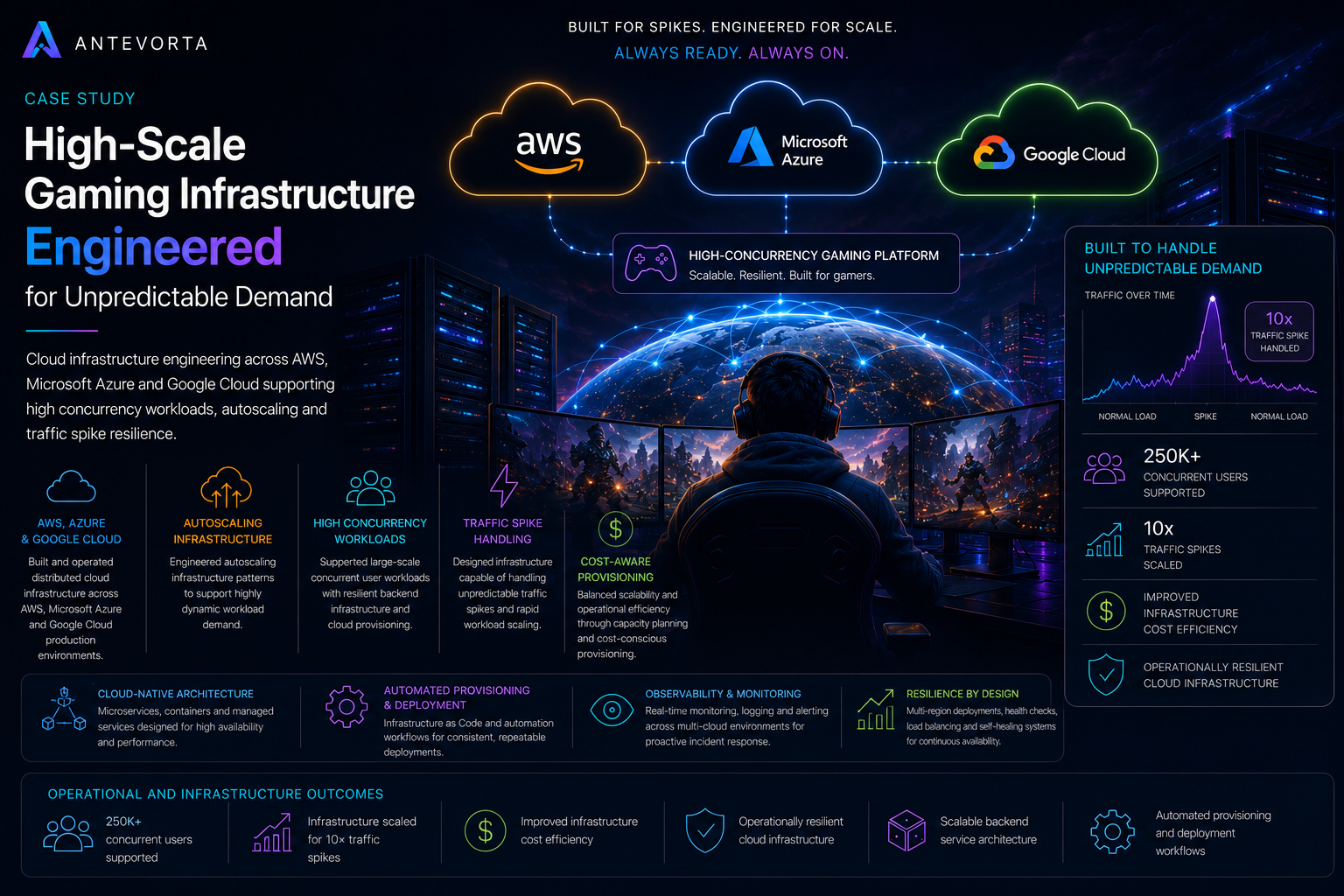
Cloud infrastructure engineering across AWS and Google Cloud supporting high concurrency workloads, autoscaling and traffic spike resilience.
Challenge
Supporting high-concurrency workloads with unpredictable traffic demand.
The engagement focused on operating gaming infrastructure supporting large-scale concurrent user activity across cloud-hosted backend systems and distributed services.
Infrastructure needed to scale rapidly during major traffic spikes while maintaining performance, operational stability and cost efficiency under highly variable workloads.
Approach
Cloud-native infrastructure designed for scalability and resilience.
Backend systems were engineered using cloud infrastructure across AWS and Google Cloud environments with automated provisioning and autoscaling deployment patterns.
Capacity planning and operational automation enabled the platform to handle rapid increases in traffic demand while maintaining service continuity and improving infrastructure efficiency.
Focus areas
Core infrastructure engineering areas
AWS & Google Cloud
Built and operated distributed cloud infrastructure across AWS and Google Cloud production environments.
Autoscaling infrastructure
Engineered autoscaling infrastructure patterns to support highly dynamic workload demand.
High concurrency workloads
Supported large-scale concurrent user workloads with resilient backend infrastructure and cloud provisioning.
Traffic spike handling
Designed infrastructure capable of handling unpredictable traffic spikes and rapid workload scaling.
Cost-aware provisioning
Balanced scalability and operational efficiency through capacity planning and cost-conscious cloud provisioning.
Delivery details
Infrastructure engineering focused on scalability and operational efficiency.
Cloud infrastructure was designed to dynamically scale in response to workload demand, enabling stable operation during rapid traffic increases and large-scale concurrent usage events.
Operational automation and infrastructure provisioning workflows improved deployment consistency while reducing manual intervention during scaling and operational events.
Cost-aware provisioning strategies balanced infrastructure availability with operational efficiency, supporting scalable growth without unnecessary cloud expenditure.
Outcomes
Operational and infrastructure outcomes
250K+ concurrent users supported
Infrastructure scaled for 10× traffic spikes
Improved infrastructure cost efficiency
Operationally resilient cloud infrastructure
Scalable backend service architecture
Automated provisioning and deployment workflows
Scaling cloud infrastructure for unpredictable demand?
Antevorta provides cloud platform engineering, autoscaling infrastructure, deployment automation and operational resilience support for high-scale production environments.
Let's talk
Ready to build a platform that scales?
Book a free 30-minute discovery call to review your infrastructure and map out clear recommendations.
- 30-minute discovery call, no obligation
- Architecture review with concrete clear recommendations
- Independent consultancy, direct, hands-on advice