Accelerated compute infrastructure engineered for AI and high-performance workloads.
Antevorta provides hands-on GPU platform engineering, Kubernetes orchestration and scalable accelerated compute infrastructure delivery across cloud-native and hybrid environments.
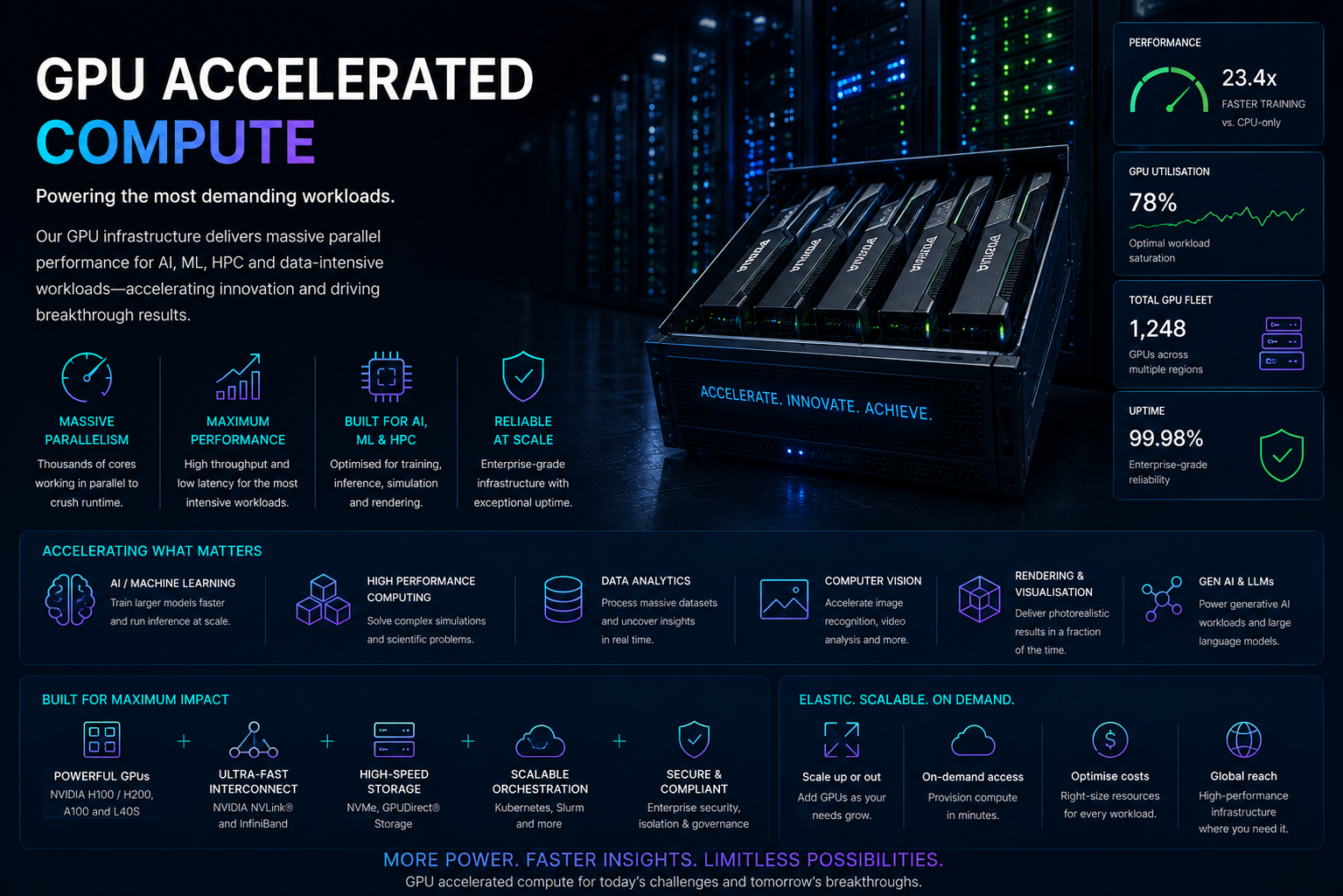
Scalable accelerated compute platforms
GPU and accelerated compute services focus on building scalable, resilient infrastructure platforms capable of supporting modern AI, machine learning and high-performance compute workloads.
Typical engagements include GPU cluster deployment, Kubernetes GPU orchestration, distributed compute environments, AI training platforms and operational optimisation for production workloads.
Production-ready AI compute engineering
Infrastructure delivery is designed around operational stability, automation and long-term scalability rather than experimental or short-lived compute environments.
Platforms are engineered to support enterprise AI operations, distributed inference systems and large-scale accelerated compute pipelines across modern cloud-native architectures.
Capabilities
GPU infrastructure and accelerated compute services
GPU infrastructure
Production-grade GPU platforms engineered for AI training, inference and high-performance compute workloads.
- GPU cluster architecture
- Multi-node compute scaling
- High-density GPU environments
- Cloud-native GPU operations
Kubernetes orchestration
Container orchestration and GPU scheduling platforms built for scalable AI and accelerated workloads.
- GPU-aware Kubernetes clusters
- Container scheduling
- Distributed workload orchestration
- Cloud-native compute automation
AI compute pipelines
Automated AI infrastructure workflows supporting training, inference and operational deployment pipelines.
- Model deployment automation
- AI workflow orchestration
- CI/CD for AI platforms
- Operational compute tooling
Hybrid & cloud GPU platforms
Flexible accelerated compute environments spanning cloud-native, hybrid and enterprise infrastructure.
- AWS & Azure GPU workloads
- Hybrid compute platforms
- Elastic compute scaling
- Multi-environment operations
Performance & observability
Operational telemetry and performance engineering for GPU-intensive production workloads.
- GPU utilisation monitoring
- Performance optimisation
- Operational telemetry
- Resilience engineering
Secure accelerated environments
Secure-by-design GPU infrastructure and operational governance for enterprise AI workloads.
- Identity & access controls
- Secure workload isolation
- Operational governance
- Network segmentation
Compute infrastructure designed for sustained performance
Accelerated compute environments require careful platform engineering across networking, orchestration, storage and operational telemetry to deliver reliable production-scale performance.
Engineering engagements focus on enabling scalable GPU operations, resilient AI infrastructure and sustainable compute architectures capable of supporting evolving enterprise AI workloads.
Typical engagement areas
- GPU cluster deployment
- Accelerated Kubernetes platforms
- AI training infrastructure
- Inference platform operations
- Distributed compute engineering
- GPU workload optimisation
- Operational AI telemetry
- Cloud-native compute automation
Delivery model
Flexible accelerated compute engineering aligned to operational scale.
GPU platform engagements are structured around operational requirements, AI workload scale and long-term infrastructure sustainability rather than fixed consultancy models.
Support is available as focused infrastructure delivery, Kubernetes engineering, AI compute platform modernisation or embedded operational engineering support.
Let's talk
Ready to build a platform that scales?
Book a free 30-minute discovery call to review your infrastructure and map out clear recommendations.
- 30-minute discovery call, no obligation
- Architecture review with concrete clear recommendations
- Independent consultancy, direct, hands-on advice